
Tech stocks took a hit on January 27, with Nvidia, Oracle, Dell, Oracle and Super Micro Computer experiencing record-breaking losses. Nvidia’s stock dropped 17%, wiping out $589 billion in market value. Meanwhile, the world’s 500 richest people collectively lost $108 billion. The reason? A small startup from Hangzhou, founded in 2023, just released its open-source AI language models.
How did a Chinese startup, without multi-billion-dollar budgets, manage to develop an AI model that outperforms advanced American counterparts? Find out in our DeepSeek AI review.
Key Models Overview
Let’s take a closer look at the specs of these new models.
Spoiler: The results will truly surprise you.
DeepSeek-R1
The DeepSeek-R1 model is 20 to 50 times cheaper to operate than OpenAI’s O1 model, depending on the task. A study by Artificial Analysis found that DeepSeek-R1 outperforms models from Google, Meta, and Anthropic in overall quality.
Like most modern LLMs, DeepSeek-R1 generates one token at a time, but it excels at math and logic problems. This is because it takes extra time to process questions by generating “thought” tokens, essentially breaking down its reasoning step by step before producing an answer.

DeepSeek-R1 found a way to get smarter without massive training expenses. Instead of spending millions collecting data, they first “grew” an auxiliary model (R1-Zero), which gathered the necessary information itself.
DeepSeek R1-Zero
The most notable innovation in DeepSeek-R1 is the creation of an intermediate model called R1-Zero, designed specifically for reasoning tasks. Unlike traditional models, R1-Zero was trained almost entirely using reinforcement learning, with minimal reliance on labeled data.
Reinforcement learning is a method where a model is rewarded for generating correct answers, allowing it to refine and generalize its knowledge over time. Impressively, R1-Zero performed on par with GPT-01 in reasoning tasks. However, it struggled with broader applications like question answering and readability.
That said, R1-Zero has a downside – while it excels at logical reasoning, it doesn’t handle everyday language and general questions as well. That’s why it serves as an intermediate step, with the main DeepSeek-R1 model receiving additional training afterward.
DeepSeek-V3
Compared to its previous version DeepSeek-R1, DeepSeek-V3 has seen significant improvements across all key parameters. The new model can process more information at once, has a notably expanded vocabulary, and features a much more powerful internal architecture. These upgrades allow it to better understand context and generate higher-quality responses.
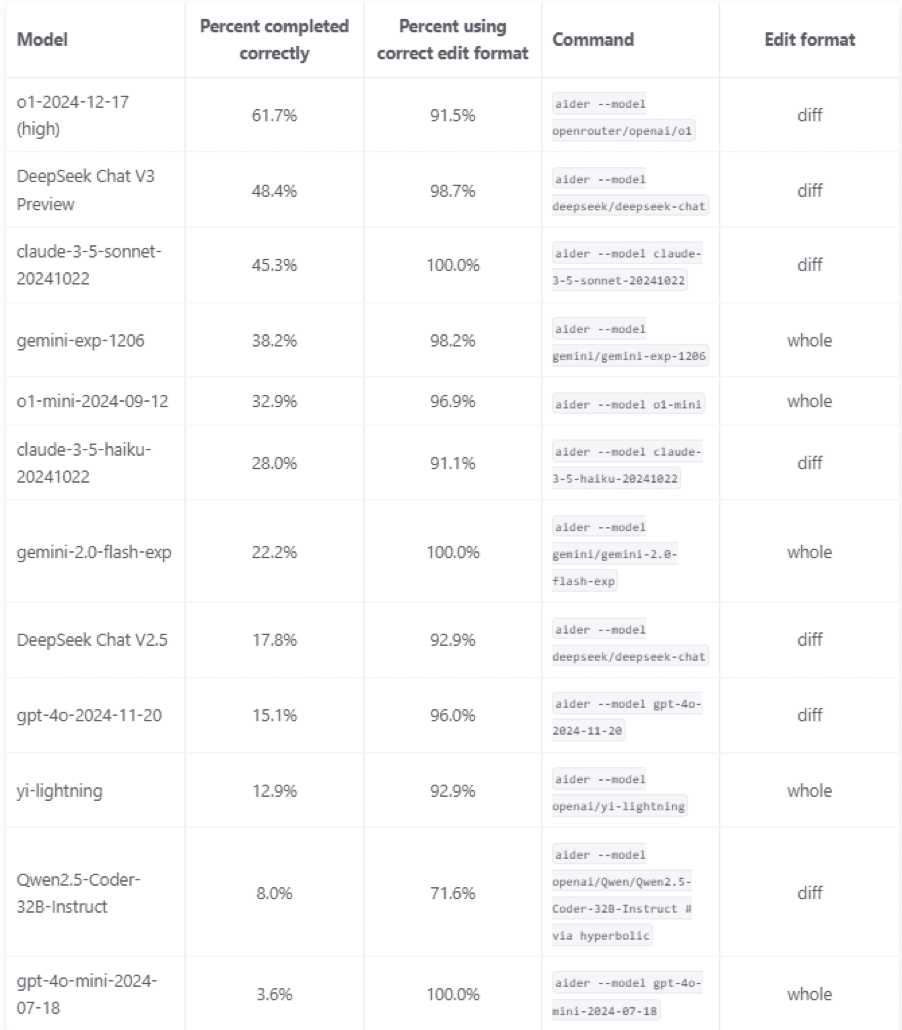
DeepSeek performance review was tested in the Aider Polyglot Benchmark, which evaluates models on 225 complex coding tasks in C++, Go, Java, JavaScript, Python, and Rust. It successfully solved 48.4% of tasks, securing second place in the rankings. While it fell short of O1-2024-12-17 (61.7%), it outperformed Claude-3.5-Sonnet-20241022 (45.3%) and Gemini-Exp-1206 (38.2%).
An important aspect of the test wasn’t just task completion but also the ability to correctly format code changes. DeepSeek-V3 excelled here, achieving an impressive 98.7% accuracy in formatting modifications.
Beyond its strong coding abilities, DeepSeek-V3 also performs well in reading diagrams, analyzing scientific texts and websites, understanding images, and assisting in content creation.
DeepSeek R1 vs. DeepSeek V3
While both models offer impressive capabilities, their differences make them suitable for different use cases.
DeepSeek-R1 stands out when solving complex tasks, offering advanced logic through a reinforcement learning (RL)-based pipeline.
On the other hand, DeepSeek-V3 excels in tasks that require significant computational resources, thanks to its scalable and efficient architecture.
Technological features and architectural innovations
DeepSeek represents a significant advancement in the field of large language models (LLMs), especially in the context of effectively solving reasoning tasks. Its architectural and technological features ensure high performance at relatively low training costs.
DeepSeek Features:
Mixture-of-Experts (MoE) Architecture:
- DeepSeek uses an MoE architecture, where the model consists of multiple specialized "experts." Only a subset of these experts is activated for each request, which allows for a significant reduction in computational costs without sacrificing performance.
Multi-Head Latent Attention (MLA) Mechanism:
- Instead of the traditional attention mechanism, DeepSeek applies MLA, which compresses information into hidden representations. This reduces the memory required to store intermediate data and speeds up the inference process.
Multi-Step Reinforcement Learning (RL):
- The predecessor model, R1-Zero, was trained exclusively using RL without prior supervised learning. This enabled the model to develop reasoning abilities comparable to advanced models, with minimal data collection and labeling costs.
Efficient Use of Computational Resources:
- Thanks to the aforementioned architectural solutions, DeepSeek-R1 has significantly lowered training costs. Compared to other LLMs like GPT-4 from OpenAI, training the Chinese model was much cheaper, making DeepSeek AI for developers more accessible.
Last year, Dario Amodei, co-founder of AI research company Anthropic, stated that training advanced AI models today costs anywhere between $100 million and $1 billion.
Meanwhile, DeepSeek claims that developing R1 cost them just $5.6 million.
Pros and Cons of DeepSeek
Pros
- Open-Source Flexibility – open-source models allow for extensive customization and innovation.
- Advanced Reasoning – excel in tasks requiring logical thinking and technical expertise.
- Scalability – designed to handle high workloads.
- Developer-Friendly – comprehensive DeepSeek API and documentation
- Privacy-Centric – a strong focus on data security and compliance.
- DeepSeek Pricing – cheaper compared to average with a price of $0.96 per 1M Tokens (blended 3:1). Input token price: $0.55, output token price: $2.19 per 1M Tokens.
Cons
- Learning Curve – the open-source nature may require technical expertise to fully leverage.
- Limited Pre-Trained Models – offers fewer pre-trained models for non-technical applications, compared to some competitor.
- DeepSeek Privacy Concerns – has recently faced significant privacy concerns, particularly regarding its open database.
Who is DeepSeek Best Suited For?
DeepSeek is ideal for:
- Developers: Its code generation AI models and debugging capabilities make it a valuable tool for software development.
- Researchers: DeepSeek advanced reasoning models are perfect for academic and technical research.
- Enterprises: Scalability and privacy features make it suitable for large organizations with complex AI needs.
- AI Enthusiasts: Open-source DeepSeek models provide a playground for experimentation and innovation.
Comparison with Top Alternatives: ChatGPT, Perplexity, and Chatsonic
Let’s compare it with three leading DeepSeek alternatives:
DeepSeek vs ChatGPT
- Strengths
DeepSeek’s open-source models and advanced reasoning capabilities give it an edge in technical applications, while ChatGPT excels in general-purpose conversational AI.
- Weaknesses
ChatGPT has a more extensive user base and broader pre-trained models, making it more accessible for non-technical users.
Sam Altman, OpenAI CEO, remained silent for a long time, but in the end, he wrote on X that DeepSeek is "impressive... especially considering what they offer for such a price."
deepseek's r1 is an impressive model, particularly around what they're able to deliver for the price.
— Sam Altman (@sama) January 28, 2025
we will obviously deliver much better models and also it's legit invigorating to have a new competitor! we will pull up some releases.
DeepSeek vs Perplexity
- Strengths
DeepSeek’s focus on technical question answering AI and code generation sets it apart from Perplexity, which is more geared towards general knowledge and research.
- Weaknesses
Perplexity offers a more user-friendly interface and is better suited for casual users.
DeepSeek vs Chatsonic
- Strengths
DeepSeek’s open-source framework and privacy features make it a better choice for developers and enterprises, while Chatsonic focuses on creative content generation.
- Weaknesses
Chatsonic’s pre-trained models for creative tasks give it an advantage in marketing and content creation.
Final Word
Despite the breakthrough by the Chinese startup DeepSeek, which has shaken up established views on the dominance of the U.S. in the AI field, President Donald Trump has already stated that the achievements of China's AI industry could be a "wake-up call" for the American Tech Sector, he is not worried about the rise of DeepSeek. Tramp is confident that the U.S. will remain dominant in this space.
But is there really nothing to worry about? If you have powerful enough computers, you can build your own artificial brain based on DeepSeek's technologies. And if your own brain is good enough, the resulting product could surpass competitors like Google, Microsoft, or OpenAI.
 HODL Team
HODL Team
Disclaimer: All materials on this site are for informational purposes only. None of the material should be interpreted as investment advice. Please note that despite the nature of much of the material created and hosted on this website, HODL FM is not a financial reference resource and the opinions of authors and other contributors are their own and should not be taken as financial advice. If you require advice of this sort, HODL FM strongly recommends contacting a qualified industry professional.


